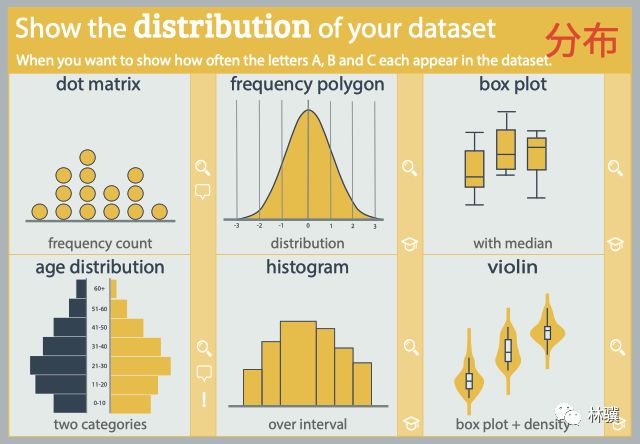
客户细分是无监督学习的最重要应用之一。通过使用群集技术,公司可以确定客户的几个细分受众群,从而使他们可以定位潜在的用户群。在这个机器学习项目中,我们将使用K-means聚类,这是聚类未标记数据集的基本算法。在继续进行此项目之前,请先了解真正的客户细分。
什么是客户细分?
客户细分是将客户群分为几组个体的过程,这些个体以与营销相关的不同方式(例如性别,年龄,兴趣和其他消费习惯)共享相似性。
部署客户细分的公司的构想是,每个客户都有不同的要求,需要进行特定的营销工作才能适当地解决它们。公司旨在获得他们所针对的客户的更深层次的方法。因此,他们的目标必须明确,并应针对每个客户的需求进行定制。此外,通过收集的数据,公司可以更深入地了解客户的喜好以及发现有价值的细分市场的需求,以使他们获得最大的利润。这样,他们可以更有效地制定营销策略,并最大程度地降低投资风险。
客户细分的技术取决于几个关键的区分因素,这些区分因素将客户分为目标群体。与人口统计,地理,经济状况以及行为模式有关的数据在确定公司应对各个细分市场的方向中起着至关重要的作用。
您可以在此处下载用于客户细分项目的数据集。
如何在R中实现客户细分?
在此数据科学项目的第一步中,我们将进行数据探索。我们将导入此角色所需的基本软件包,然后阅读我们的数据。最后,我们将遍历输入数据以获得必要的见解。
代码:
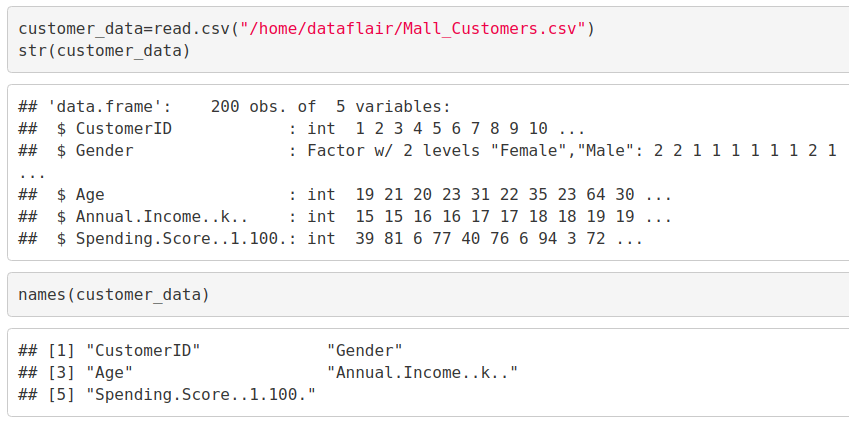
customer_data=read.csv("/home/dataflair/Mall_Customers.csv") str(customer_data) names(customer_data)
输出截图:
现在,我们将使用head()函数显示数据集的前六行,并使用summary()函数输出其摘要。
码:
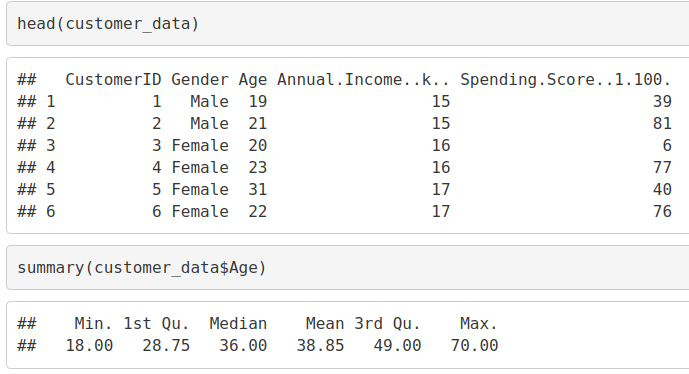
head(customer_data) summary(customer_data$Age)
输出截图:
码:
sd(customer_data$Age) summary(customer_data$Annual.Income..k..) sd(customer_data$Annual.Income..k..) summary(customer_data$Age)
输出截图:

码:
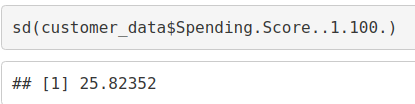
sd(customer_data$Spending.Score..1.100.)
输出截图:
您是否检查过DataFlair的数据科学趋势项目?必须检查– 使用R进行情感分析
客户性别可视化
在此,我们将创建一个条形图和一个饼图,以显示跨我们的customer_data数据集的性别分布。
码:
a=table(customer_data$Gender) barplot(a,main="Using BarPlot to display Gender Comparision", ylab="Count", xlab="Gender", col=rainbow(2), legend=rownames(a))
屏幕截图:
输出:
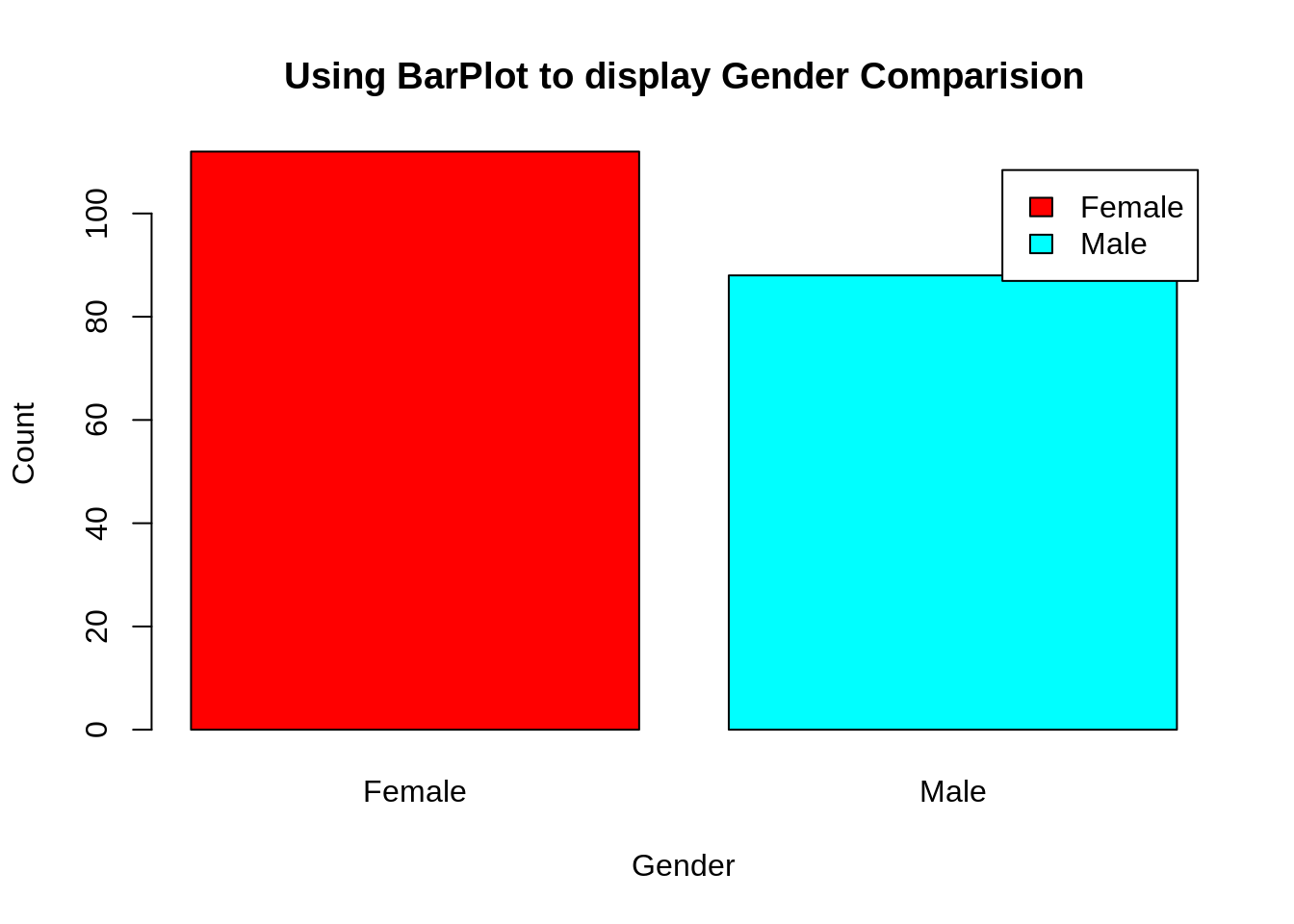
从上面的小图中,我们观察到女性的数量高于男性。现在,让我们可视化饼图以观察男女分布的比例。
码:
pct=round(a/sum(a)*100) lbs=paste(c("Female","Male")," ",pct,"%",sep=" ") library(plotrix) pie3D(a,labels=lbs, main="Pie Chart Depicting Ratio of Female and Male")
屏幕截图:

输出:
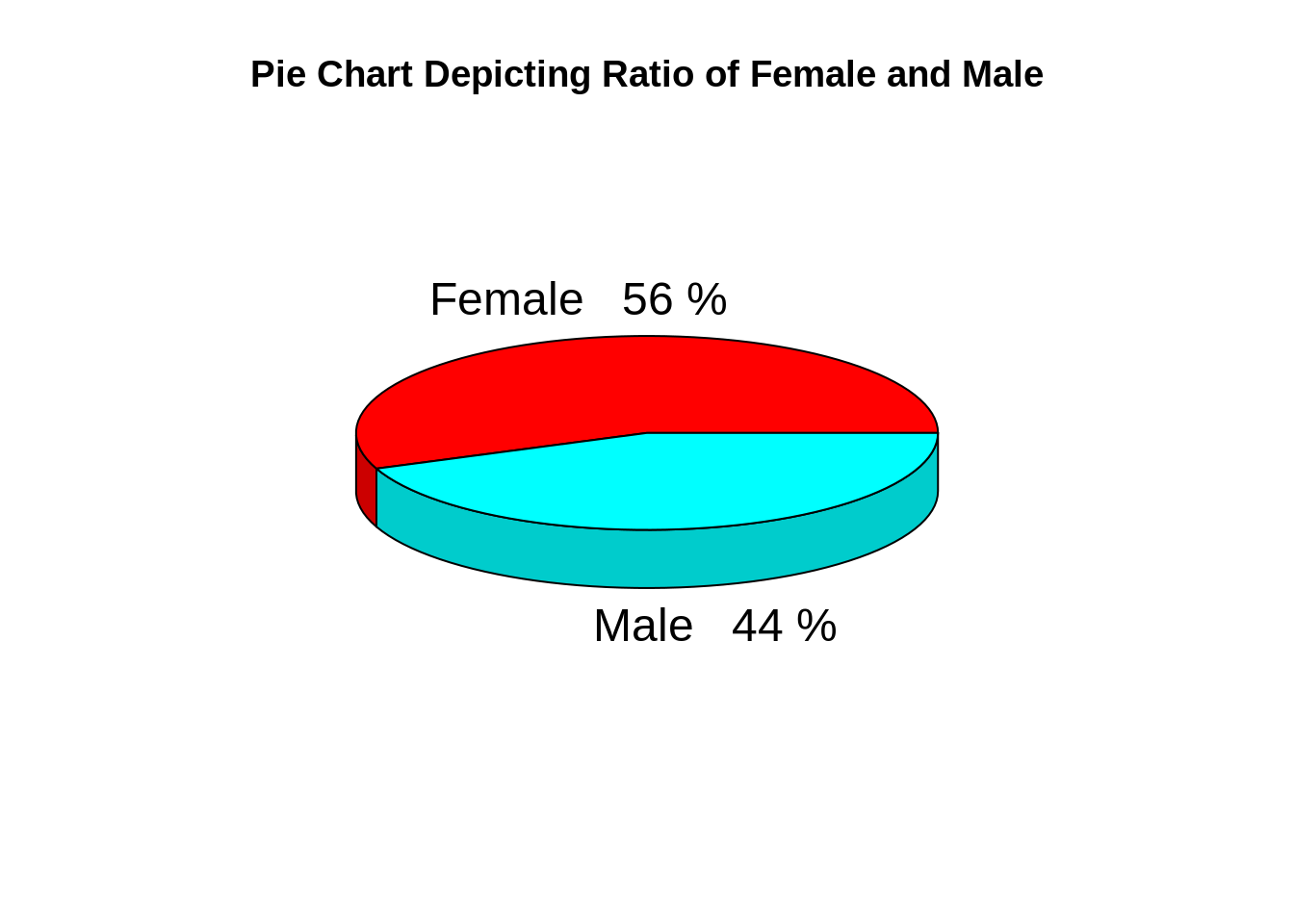
从上图可以得出结论,在客户数据集中,女性的比例为56%,而男性的比例为44%。
年龄分布的可视化
让我们绘制直方图以查看分布以绘制客户年龄的频率。首先,我们将总结Age变量。
码:
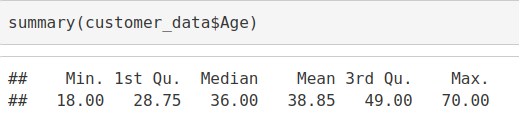
summary(customer_data$Age)
输出截图:
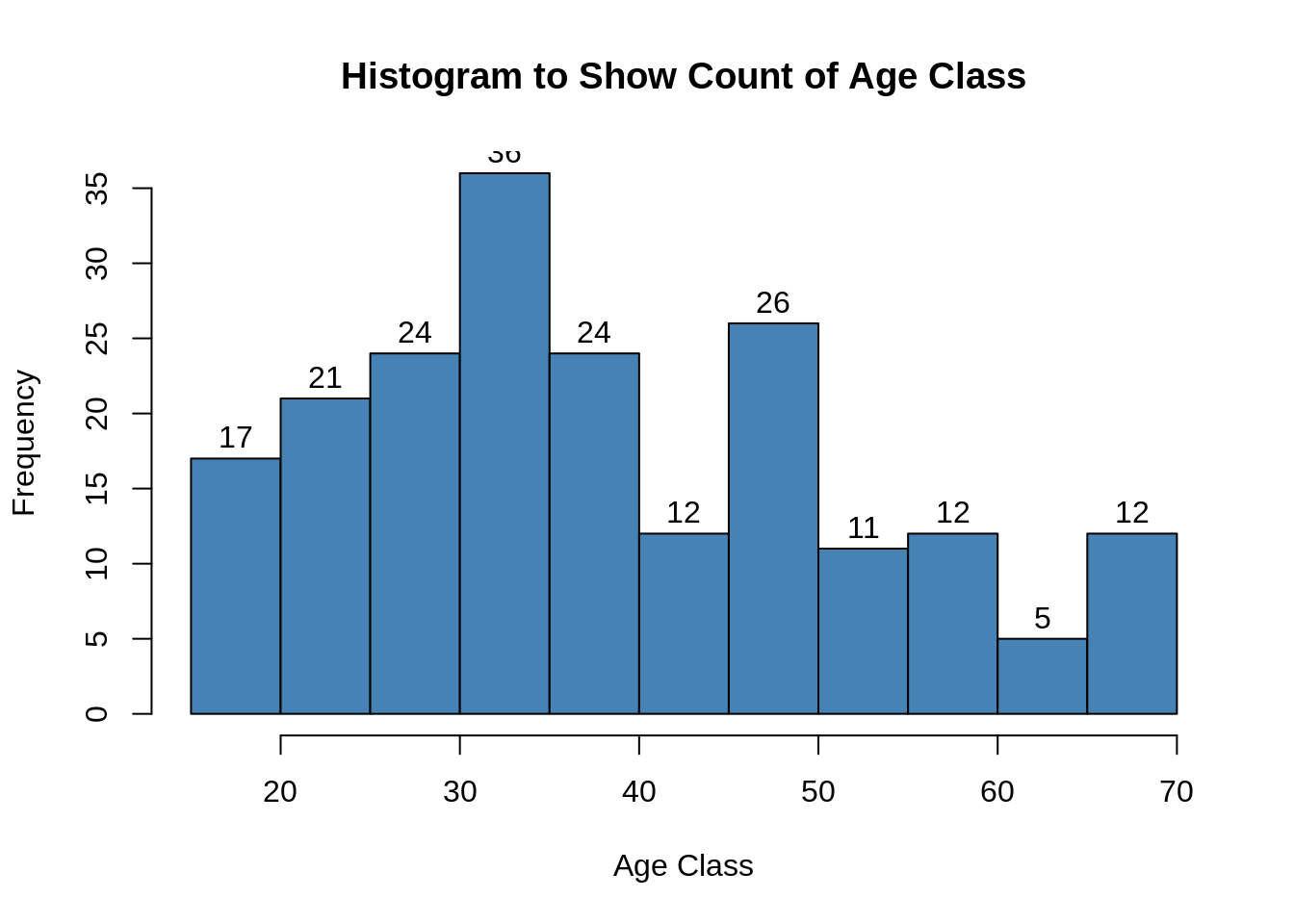
码:
hist(customer_data$Age, col="blue", main="Histogram to Show Count of Age Class", xlab="Age Class", ylab="Frequency", labels=TRUE)
屏幕截图:

输出:
码:
boxplot(customer_data$Age, col="ff0066", main="Boxplot for Descriptive Analysis of Age")
屏幕截图:

输出:
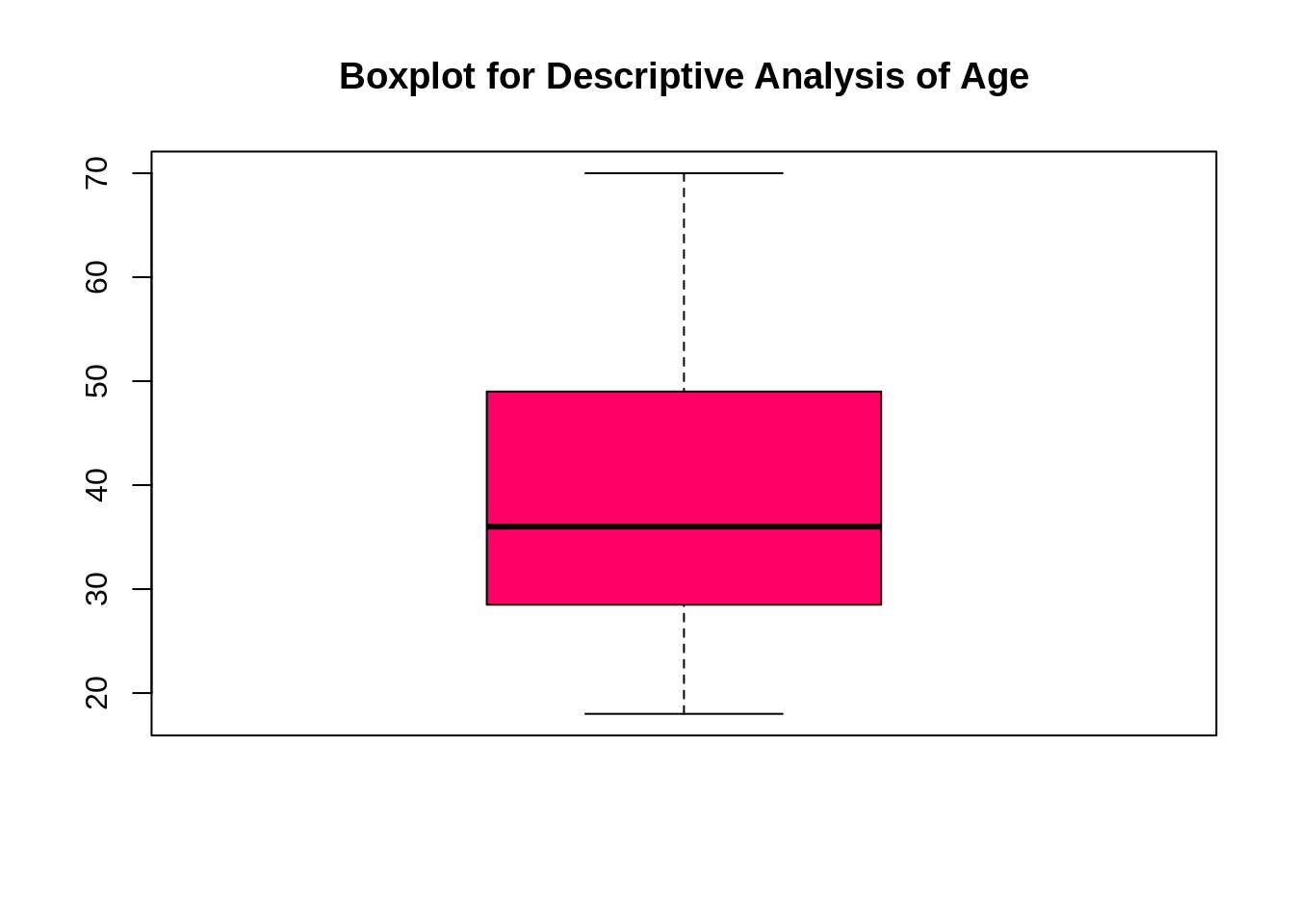
通过以上两个可视化,我们得出最大客户年龄在30到35之间。最小客户年龄是18,而最大年龄是70。
不要忘记练习机器学习的 信用卡欺诈检测项目
客户年收入分析
在R项目的这一部分中,我们将创建可视化工具来分析客户的年收入。我们将绘制直方图,然后使用密度图检查该数据。
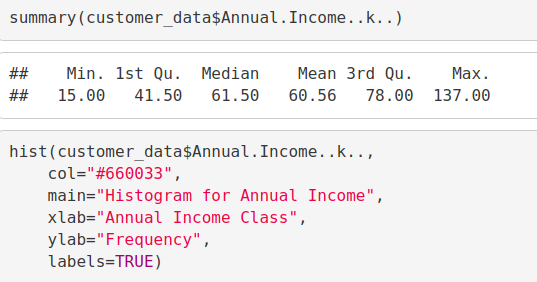
码:
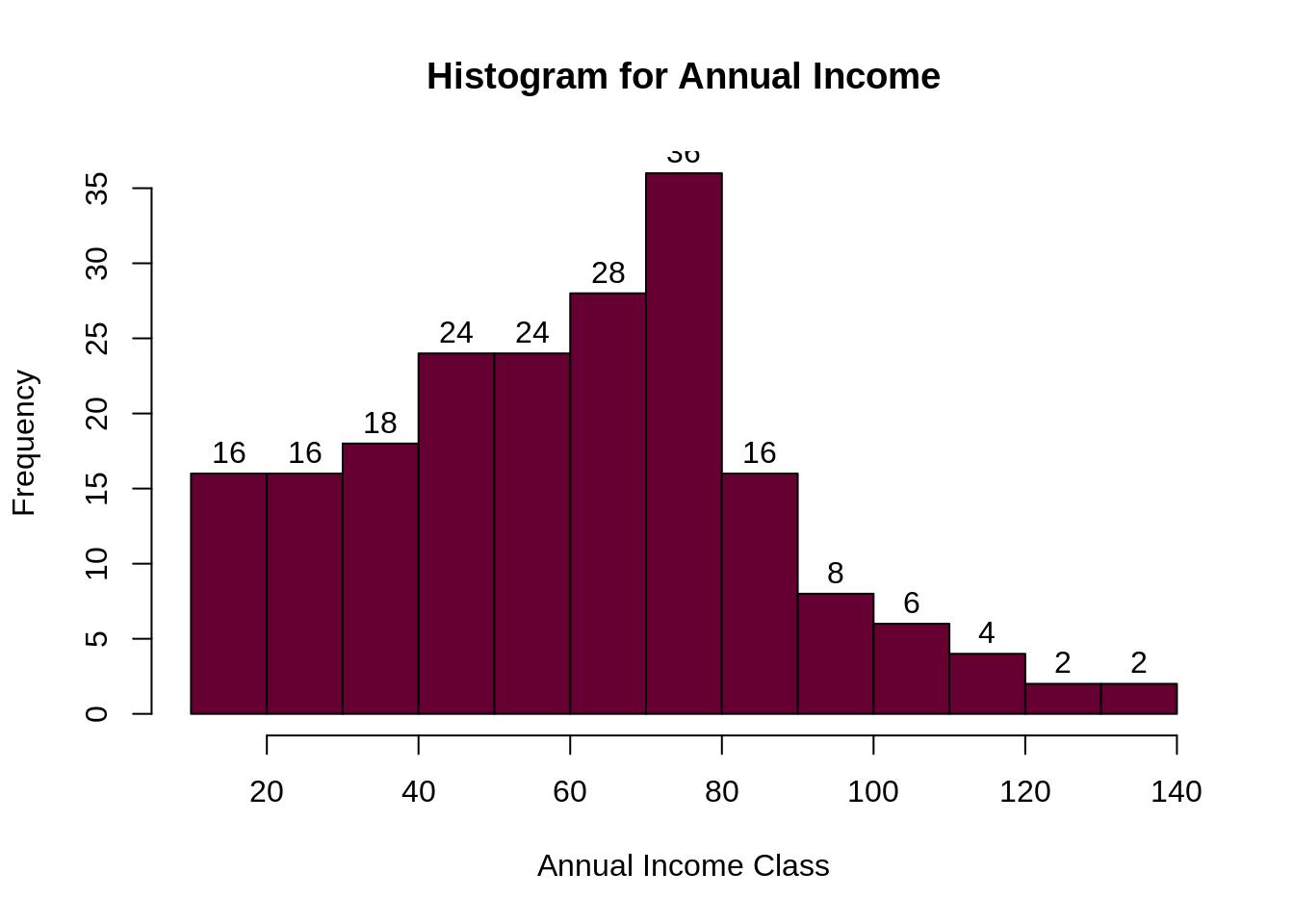
summary(customer_data$Annual.Income..k..) hist(customer_data$Annual.Income..k.., col="#660033", main="Histogram for Annual Income", xlab="Annual Income Class", ylab="Frequency", labels=TRUE)
屏幕截图:
输出:
码:
plot(density(customer_data$Annual.Income..k..), col="yellow", main="Density Plot for Annual Income", xlab="Annual Income Class", ylab="Density") polygon(density(customer_data$Annual.Income..k..), col="#ccff66")
屏幕截图:
输出:
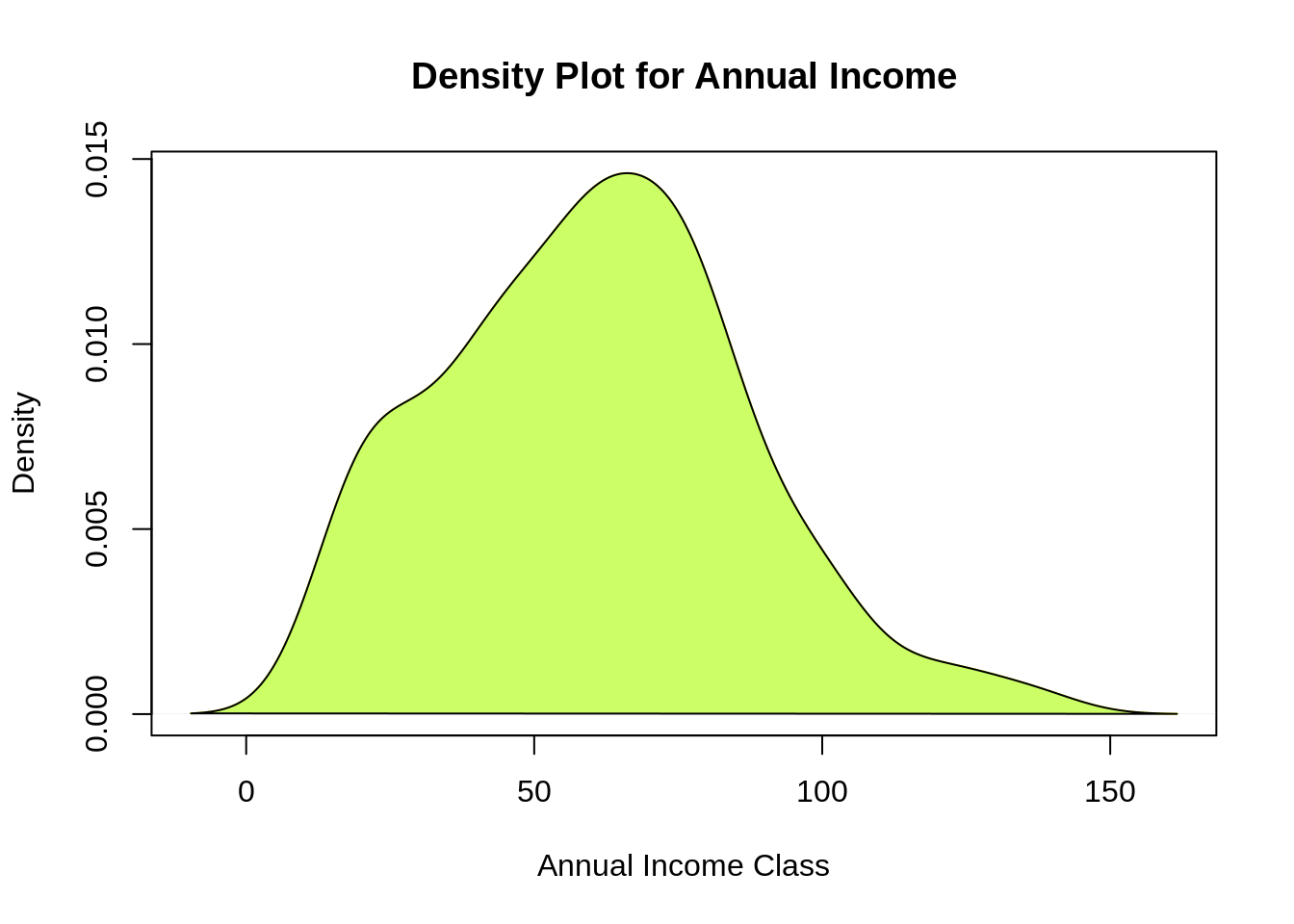
通过以上描述性分析,我们得出结论,客户的最小年收入为15,最大收入为137。平均收入为70的人在我们的直方图分布中具有最高的频率计数。所有客户的平均工资为60.56。在上面显示的内核密度图中,我们看到年收入具有正态分布。
分析客户的消费得分
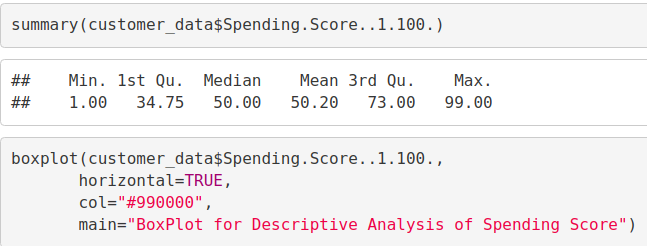
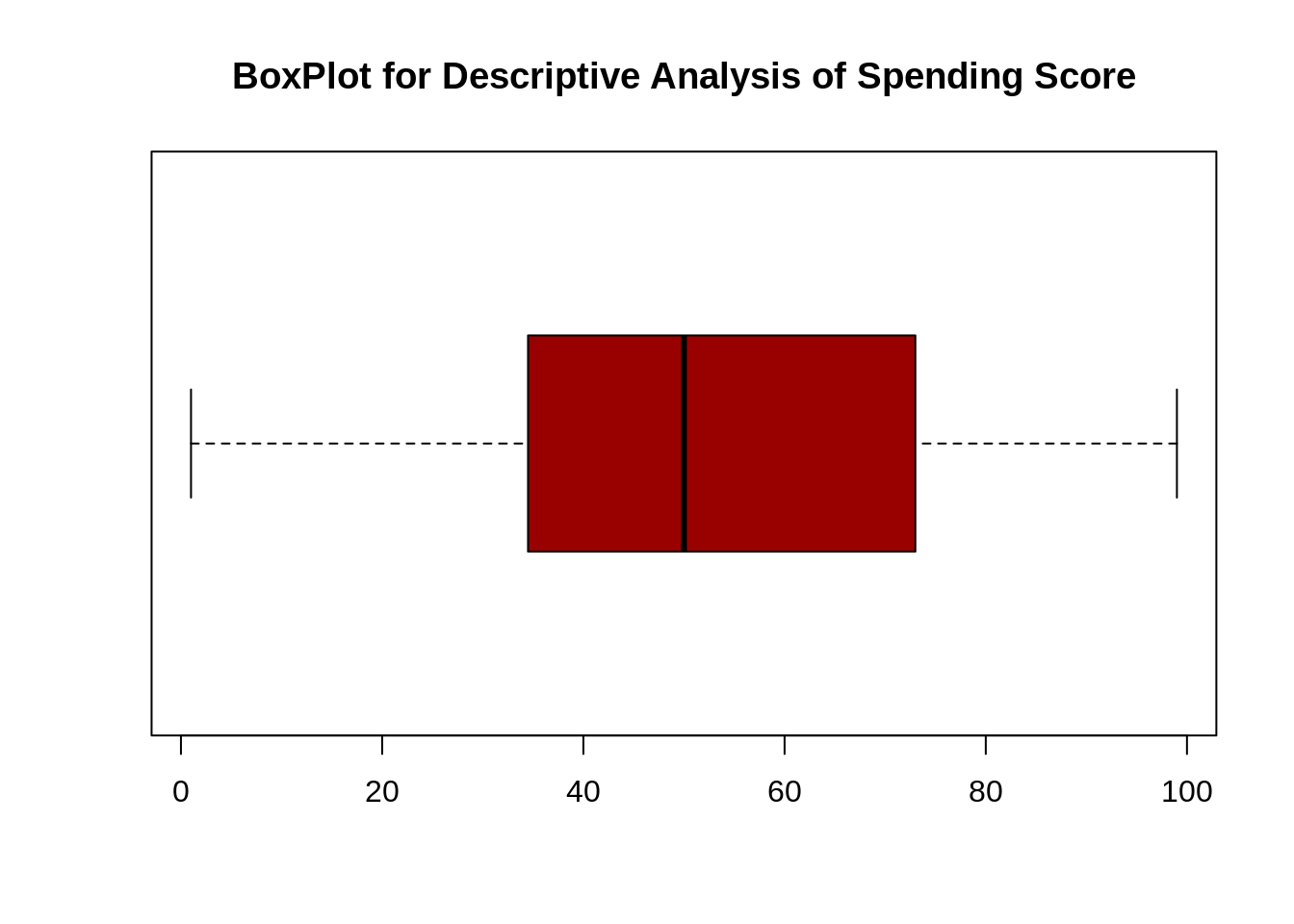
summary(customer_data$Spending.Score..1.100.) Min. 1st Qu. Median Mean 3rd Qu. Max. ## 1.00 34.75 50.00 50.20 73.00 99.00 boxplot(customer_data$Spending.Score..1.100., horizontal=TRUE, col="#990000", main="BoxPlot for Descriptive Analysis of Spending Score")
屏幕截图:
输出:
码:
hist(customer_data$Spending.Score..1.100., main="HistoGram for Spending Score", xlab="Spending Score Class", ylab="Frequency", col="#6600cc", labels=TRUE)
屏幕截图:

输出:
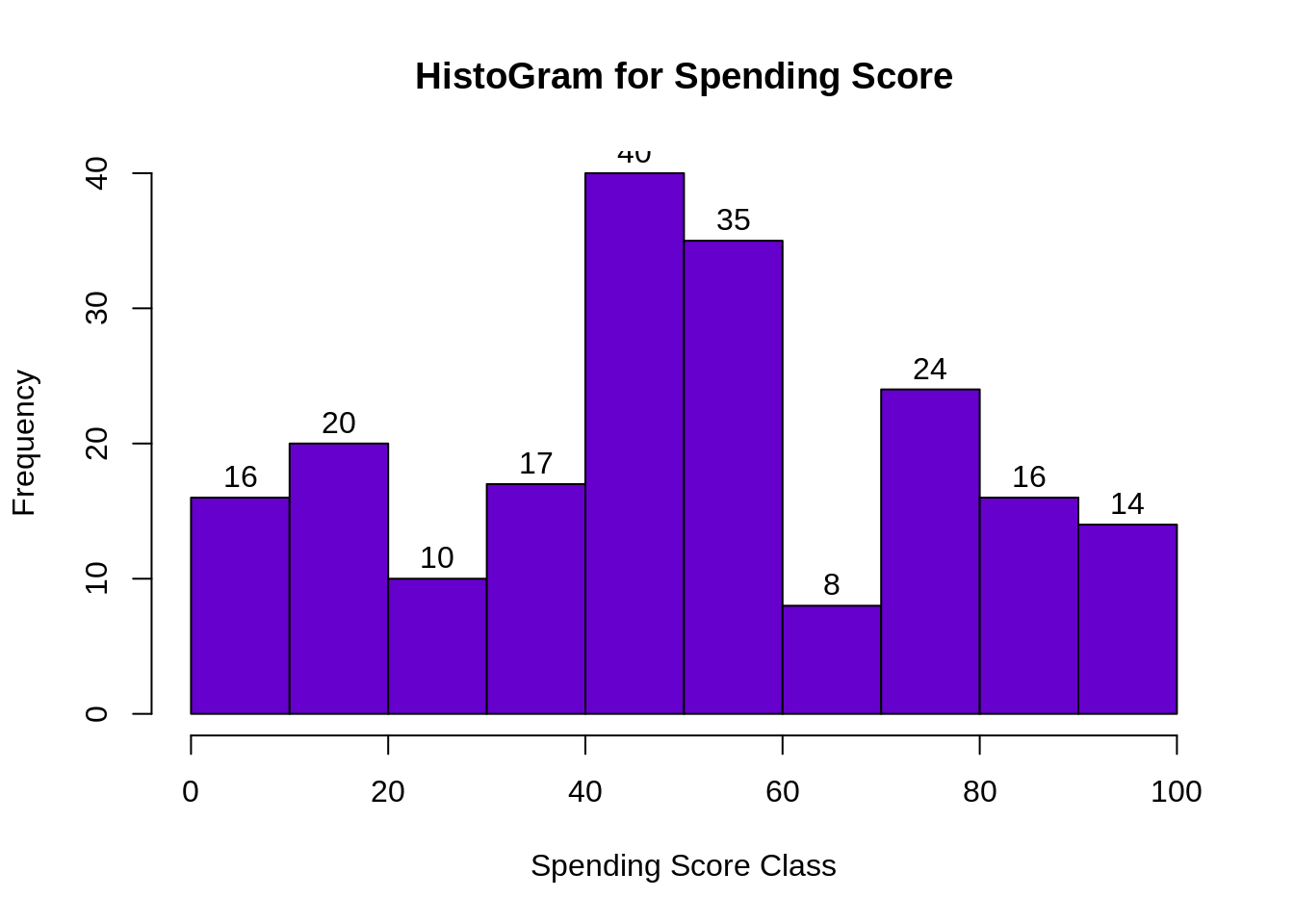
最低支出得分为1,最高为99,平均为50.20。我们可以看到支出得分的描述性分析是:最小值为1,最大值为99,平均。是50.20。根据直方图,我们得出结论,在所有类别中,介于40级和50级之间的客户的支出得分最高。
K均值算法
在使用k均值聚类算法时,第一步是指出我们希望在最终输出中产生的聚类数(k)。该算法首先从数据集中随机选择k个对象,这些对象将作为我们聚类的初始中心。这些选定的对象是聚类平均值,也称为质心。然后,其余对象将分配最接近的质心。该质心由对象与聚类均值之间的欧几里得距离定义。我们将此步骤称为“集群分配”。分配完成后,算法将继续计算数据中存在的每个聚类的新平均值。重新计算中心后,将检查观察值是否更接近其他聚类。使用更新的聚类均值,可以对对象进行重新分配。这将反复进行几次迭代,直到集群分配停止更改为止。当前迭代中存在的群集与先前迭代中获得的群集相同。
如果您想应对主要挑战之一,那么知识大数据至关重要。因此,我建议您查看Hadoop for Data Science。
总结K均值聚类–
我们指定需要创建的集群数量。
该算法从数据集中随机选择k个对象。该对象是初始聚类或均值。
最接近的质心获得新观测值的分配。我们基于对象和质心之间的欧几里得距离进行此分配。
数据点中的k个簇通过计算出现在簇的所有数据点中的新平均值来更新质心。第k个聚类的质心的长度为p,其中包含第k个聚类中用于观察的所有变量的均值。我们用p表示变量数。
在平方和内迭代最小化总和。然后,通过平方的总和的迭代最小化,当我们实现最大迭代时,分配停止动摇。R软件用于最大迭代的默认值为10。
确定最佳聚类
使用群集时,需要指定要使用的群集数量。您想利用最佳数量的群集。为了帮助您确定最佳集群,有以下三种流行的方法–
肘法
轮廓法
差距统计
肘法
像k-means这样的集群分区方法背后的主要目标是定义集群,以使集群内变化保持最小。
minimize(sum W(Ck)), k=1…k
其中Ck表示第k个群集,W(Ck)表示群集内变化。通过测量整个集群内部变化,可以评估聚类边界的紧密度。然后,我们可以如下定义最佳群集–
首先,我们为k的多个值计算聚类算法。这可以通过在k范围内创建1到10个簇的变化来完成。然后,我们计算集群内的总平方和(iss)。然后,我们基于k个簇的数量绘制iss。此图表示模型中所需的适当簇数。在该图中,弯曲或膝盖的位置指示了最佳簇数。让我们在R中实现此操作如下-
码:
library(purrr) set.seed(123) # function to calculate total intra-cluster sum of square iss <- function(k) { kmeans(customer_data[,3:5],k,iter.max=100,nstart=100,algorithm="Lloyd" )$tot.withinss } k.values <- 1:10 iss_values <- map_dbl(k.values, iss) plot(k.values, iss_values, type="b", pch = 19, frame = FALSE, xlab="Number of clusters K", ylab="Total intra-clusters sum of squares")
屏幕截图:
输出:
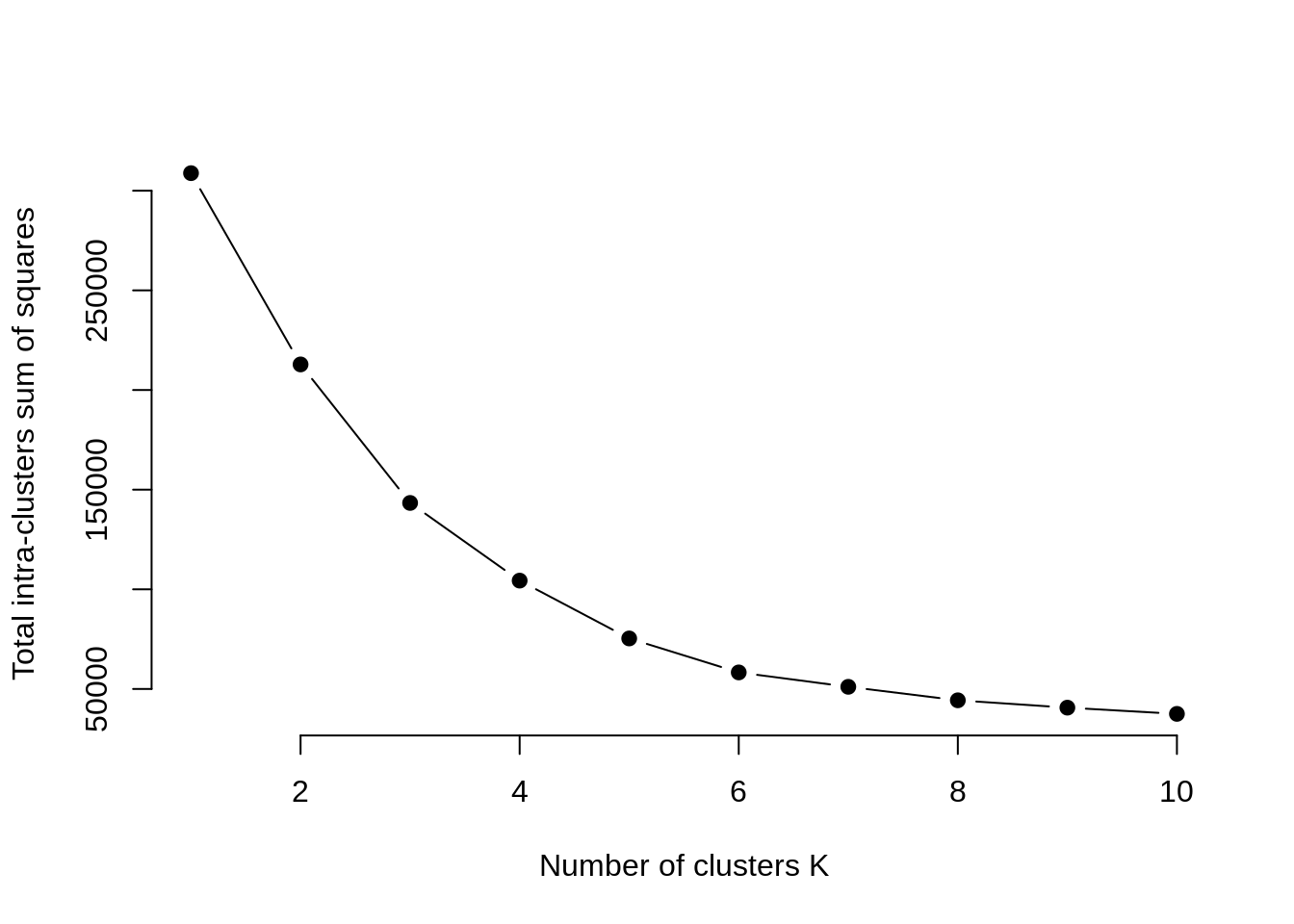
从上图可以得出结论,认为4是适当的簇数,因为它似乎出现在肘部曲线的折弯处。
想成为下一位数据科学家吗?遵循行业专家的DataFlair指南设计,轻松地成为数据科学家
平均轮廓法
借助于平均轮廓法,我们可以测量聚类操作的质量。这样,我们可以确定数据对象在群集中的状态。如果我们获得高的平均轮廓宽度,则意味着我们具有良好的聚类。平均轮廓法计算不同k值的轮廓观测值的平均值。有了k个群集的最佳数量,就可以使k个群集的有效轮廓上的平均轮廓最大化。
使用群集程序包中的轮廓函数,我们可以使用kmean函数计算平均轮廓宽度。在这里,最佳集群将具有最高的平均值。
码:
library(cluster) library(gridExtra) library(grid) k2<-kmeans(customer_data[,3:5],2,iter.max=100,nstart=50,algorithm="Lloyd") s2<-plot(silhouette(k2$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:
输出:

码:
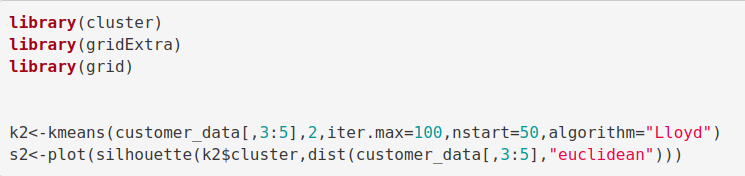
k3<-kmeans(customer_data[,3:5],3,iter.max=100,nstart=50,algorithm="Lloyd") s3<-plot(silhouette(k3$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
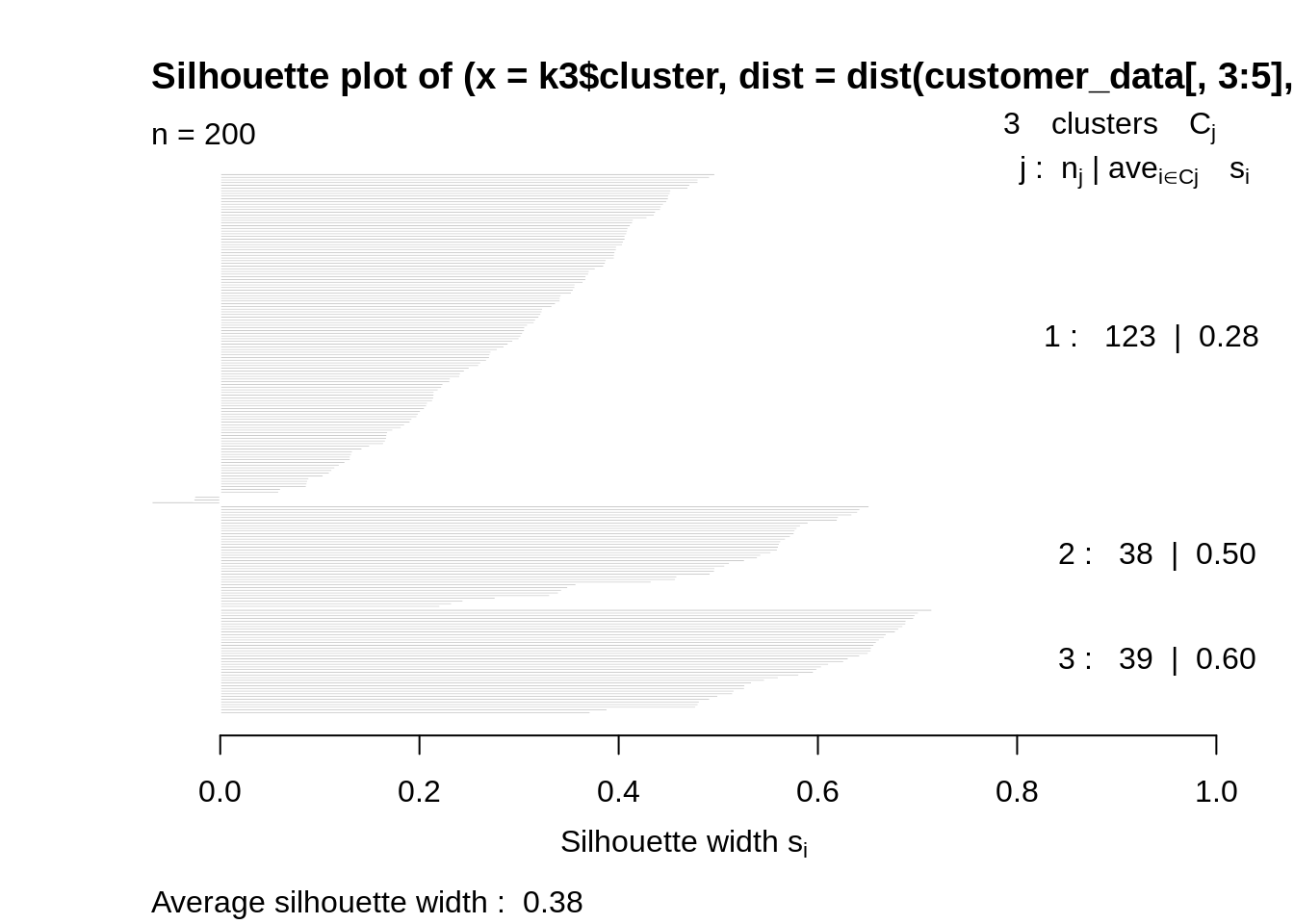
k4<-kmeans(customer_data[,3:5],4,iter.max=100,nstart=50,algorithm="Lloyd") s4<-plot(silhouette(k4$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
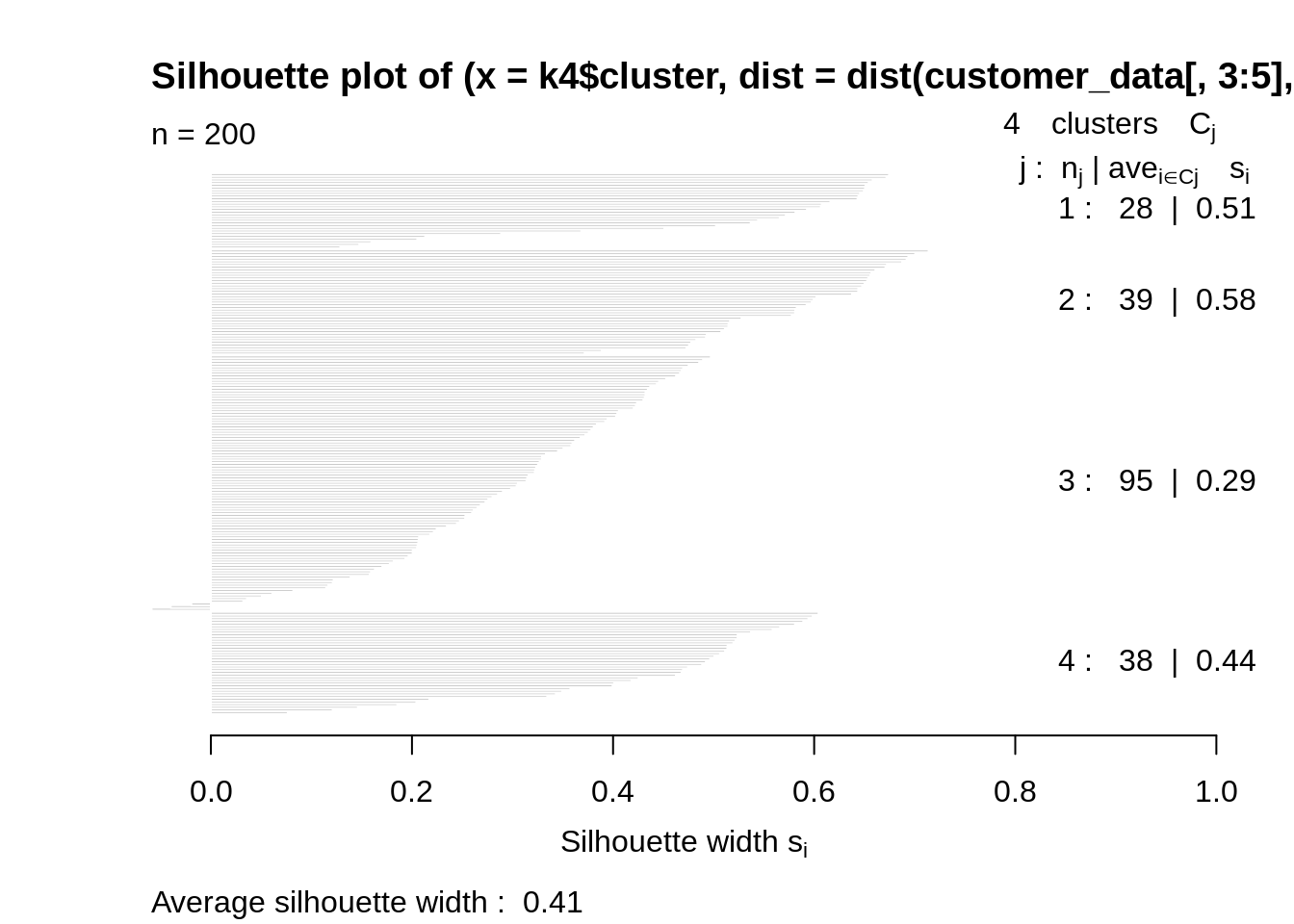
k5<-kmeans(customer_data[,3:5],5,iter.max=100,nstart=50,algorithm="Lloyd") s5<-plot(silhouette(k5$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
k6<-kmeans(customer_data[,3:5],6,iter.max=100,nstart=50,algorithm="Lloyd") s6<-plot(silhouette(k6$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
k7<-kmeans(customer_data[,3:5],7,iter.max=100,nstart=50,algorithm="Lloyd") s7<-plot(silhouette(k7$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
k8<-kmeans(customer_data[,3:5],8,iter.max=100,nstart=50,algorithm="Lloyd") s8<-plot(silhouette(k8$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
k9<-kmeans(customer_data[,3:5],9,iter.max=100,nstart=50,algorithm="Lloyd") s9<-plot(silhouette(k9$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
码:
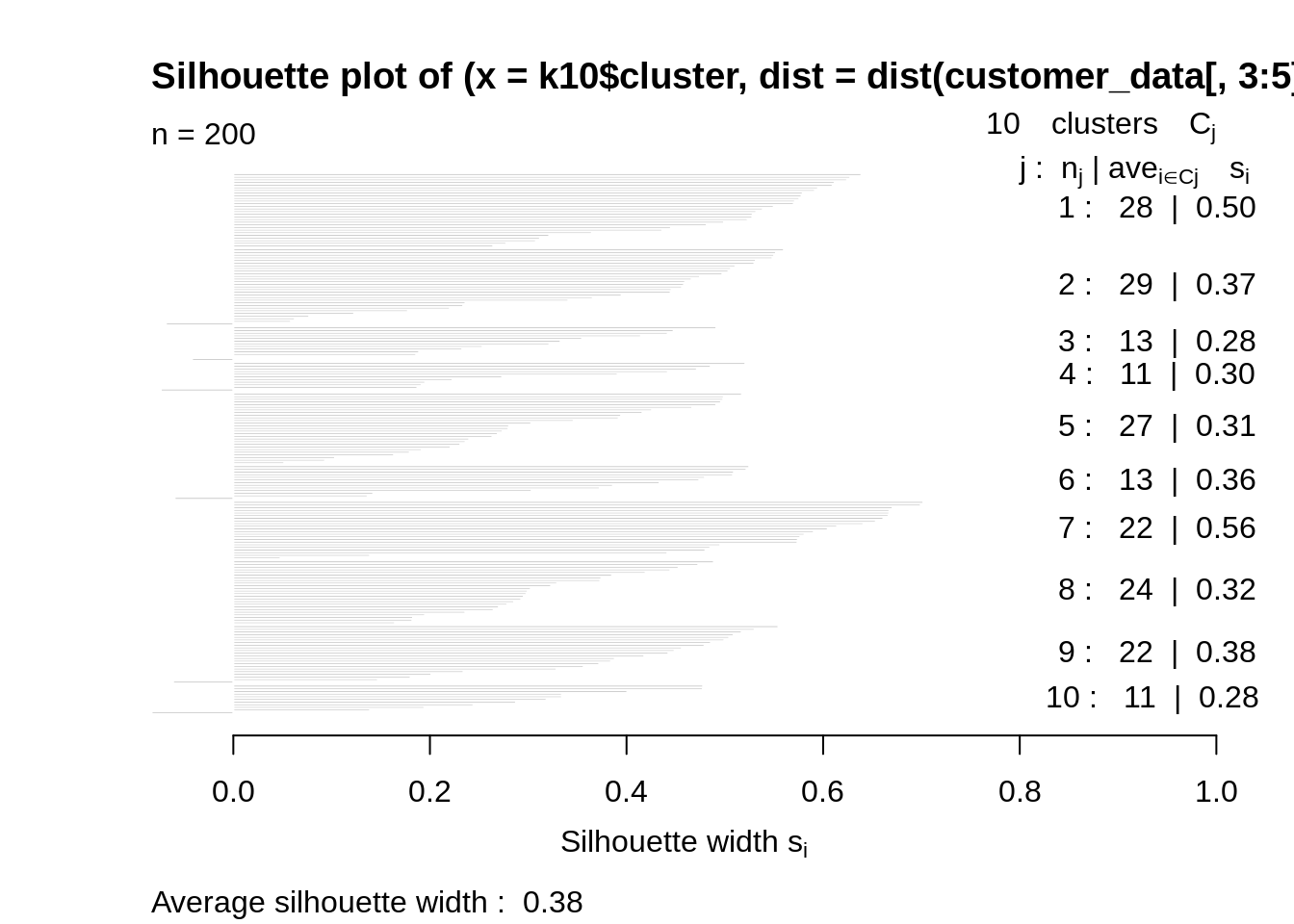
k10<-kmeans(customer_data[,3:5],10,iter.max=100,nstart=50,algorithm="Lloyd") s10<-plot(silhouette(k10$cluster,dist(customer_data[,3:5],"euclidean")))
屏幕截图:

输出:
现在,我们使用fviz_nbclust()函数确定并可视化集群的最佳数量,如下所示–
码:
library(NbClust)
library(factoextra)
fviz_nbclust(customer_data[,3:5], kmeans, method = "silhouette")
屏幕截图:
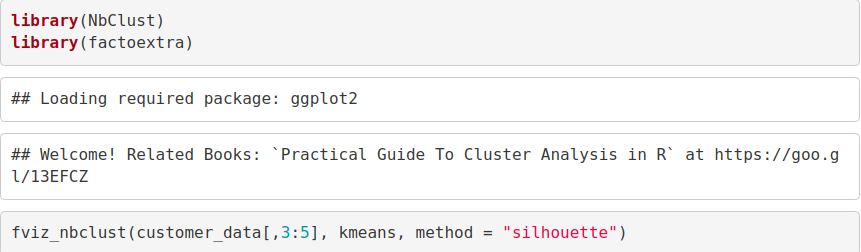
输出:
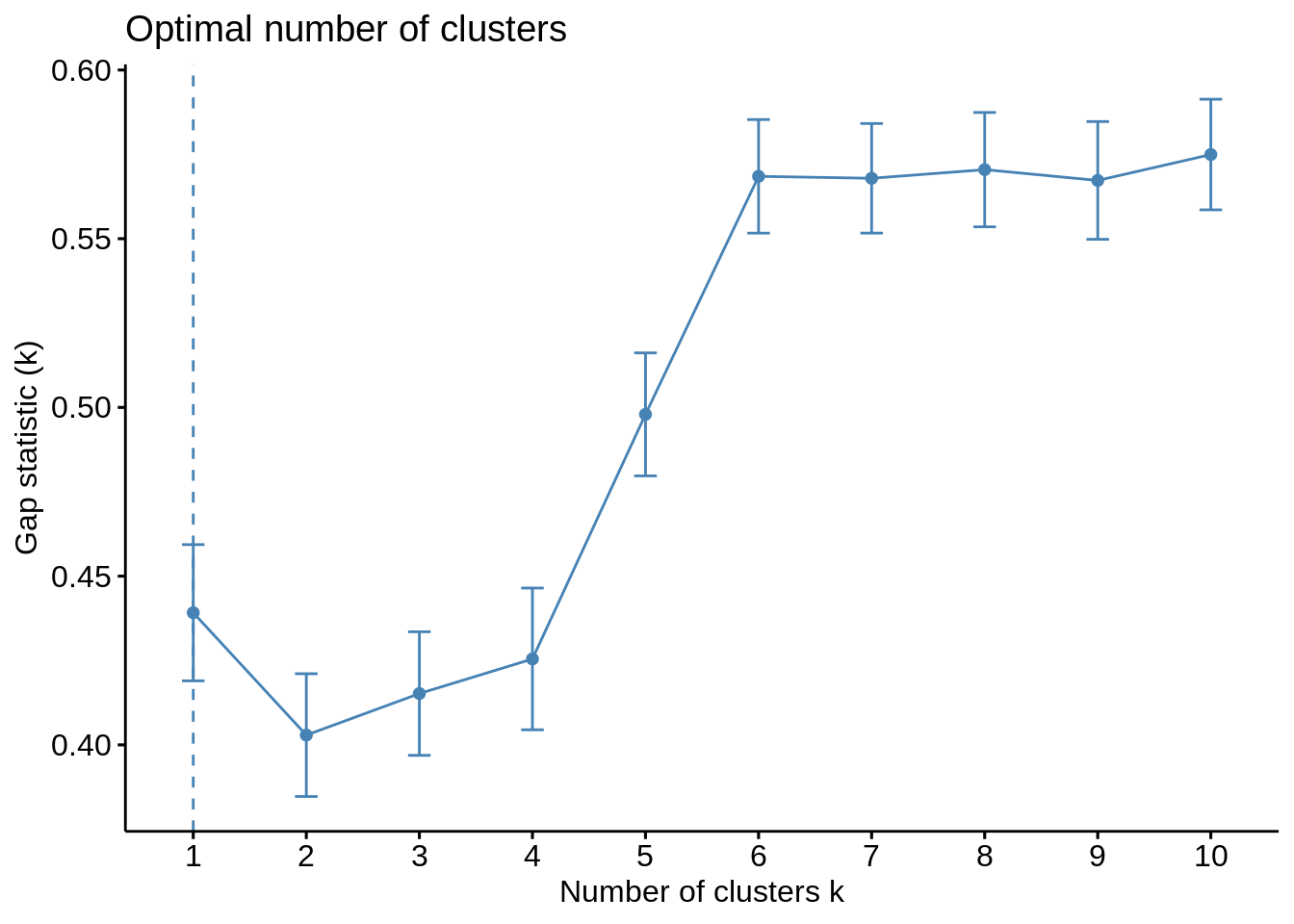
差距统计法
在2001年,斯坦福大学的研究人员-R. Tibshirani,G.Walther和T. Hastie发表了差距统计方法。我们可以将这种方法用于任何聚类方法,例如K均值,层次聚类等。使用空白统计量,可以比较不同k值的总集群内变化及其在空引用数据分布下的预期值。借助蒙特卡洛模拟,可以生成样本数据集。对于数据集中的每个变量,我们可以计算min(xi)和max(xj)之间的范围,通过该范围我们可以均匀地产生从区间下限到上限的值。
为了计算间隙统计方法,我们可以利用clusGap函数为给定的输出提供间隙统计以及标准误差。
码:
set.seed(125) stat_gap <- clusGap(customer_data[,3:5], FUN = kmeans, nstart = 25, K.max = 10, B = 50) fviz_gap_stat(stat_gap)
屏幕截图:

输出:
免费学习有关机器学习的所有内容–检查90多种免费机器学习教程
现在,让我们以k = 6作为最佳聚类–
码:
k6<-kmeans(customer_data[,3:5],6,iter.max=100,nstart=50,algorithm="Lloyd") k6
输出截图:
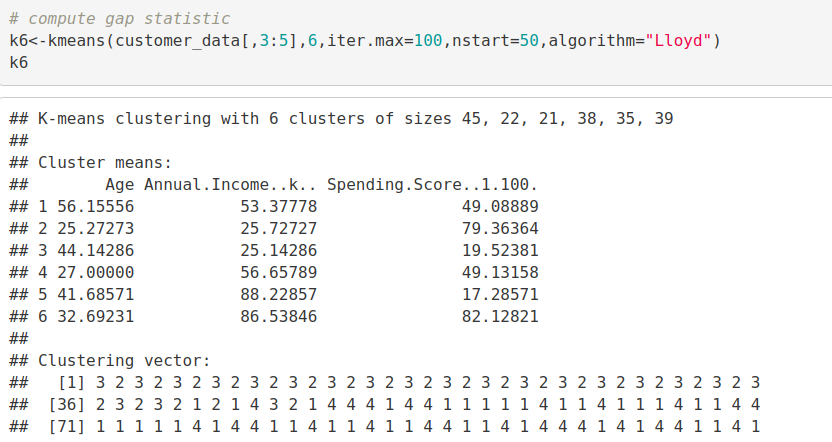
在kmeans运算的输出中,我们观察到包含一些关键信息的列表。由此,我们得出的有用信息是–
cluster –这是一个由多个整数组成的向量,表示每个点都有分配的群集。
totss –代表平方和。
centers –由几个集群中心组成的矩阵
innerss –这是一个向量,表示每个簇具有一个分量的簇内平方和。
tot.withinss –表示集群内的总平方和。
betweenss –这是集群之间的平方之和。
size –每个集群持有的总点数。
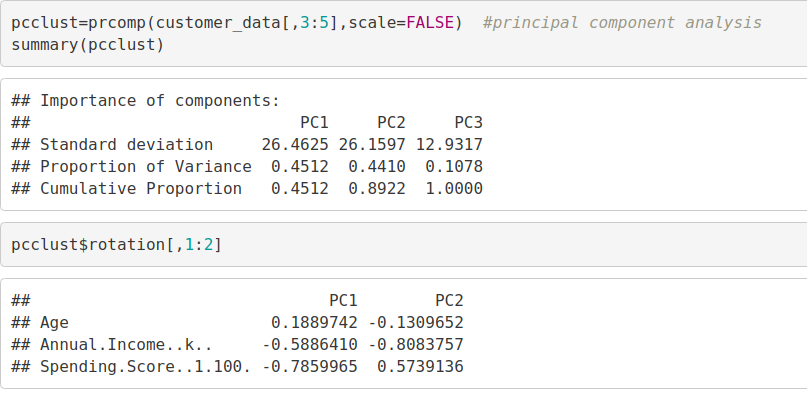
使用前两个主要组件可视化聚类结果
码:
pcclust=prcomp(customer_data[,3:5],scale=FALSE) #principal component analysis summary(pcclust) pcclust$rotation[,1:2]
输出截图:
码:
set.seed(1) ggplot(customer_data, aes(x =Annual.Income..k.., y = Spending.Score..1.100.)) + geom_point(stat = "identity", aes(color = as.factor(k6$cluster))) + scale_color_discrete(name=" ", breaks=c("1", "2", "3", "4", "5","6"), labels=c("Cluster 1", "Cluster 2", "Cluster 3", "Cluster 4", "Cluster 5","Cluster 6")) + ggtitle("Segments of Mall Customers", subtitle = "Using K-means Clustering")
屏幕截图:

输出:
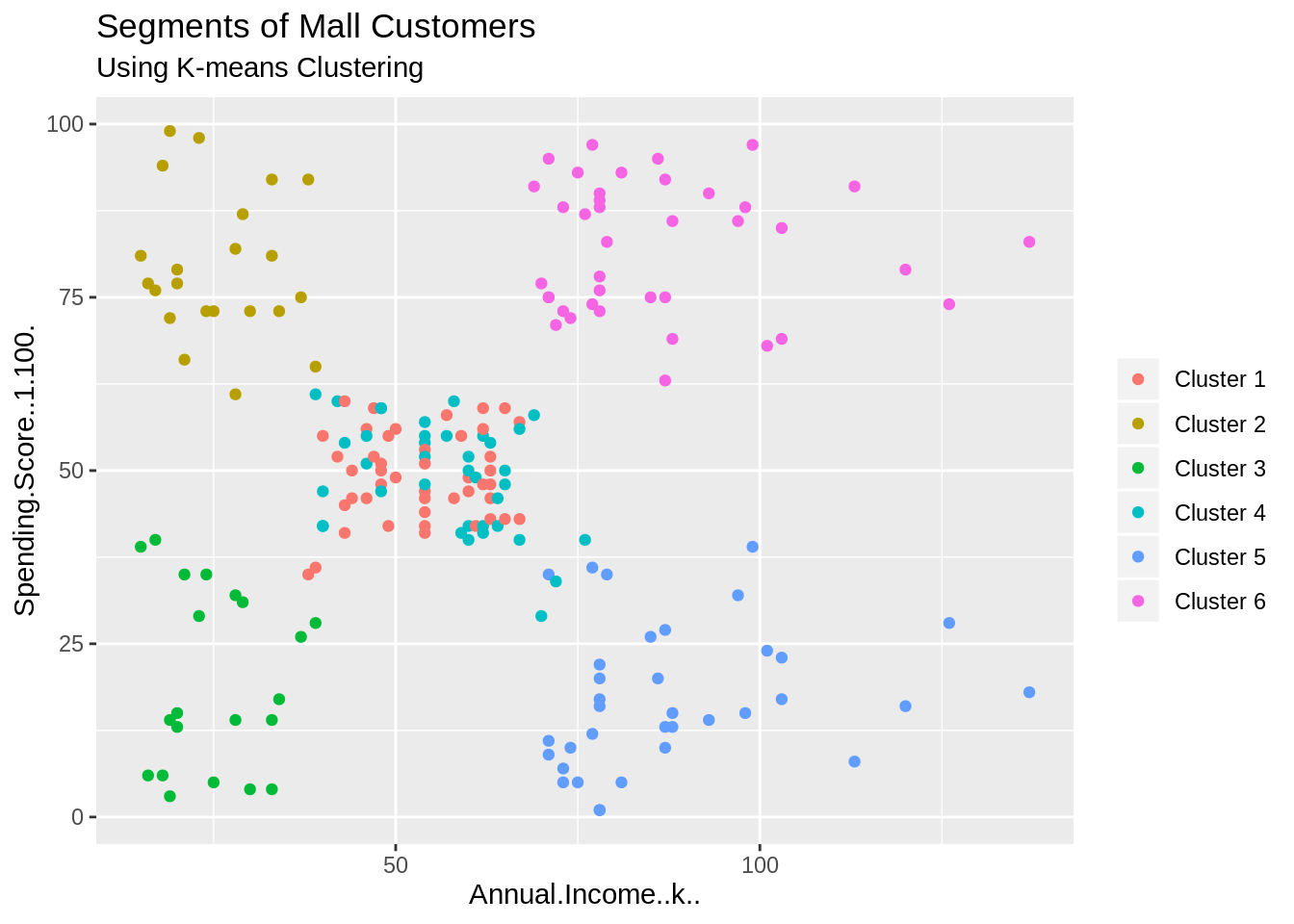
通过以上可视化,我们观察到有6个簇的分布如下:
集群6和4 –这些集群代表具有中等收入薪水和中等年薪支出的customer_data。
群集1 –该群集表示具有高年收入和高年度支出的customer_data。
集群3 –该集群表示年收入低且年支出低的customer_data。
类别2 –该类别表示较高的年收入和较低的年支出。
类别5 –该类别的年收入较低,但其年度支出较高。
码:
ggplot(customer_data, aes(x =Spending.Score..1.100., y =Age)) + geom_point(stat = "identity", aes(color = as.factor(k6$cluster))) + scale_color_discrete(name=" ", breaks=c("1", "2", "3", "4", "5","6"), labels=c("Cluster 1", "Cluster 2", "Cluster 3", "Cluster 4", "Cluster 5","Cluster 6")) + ggtitle("Segments of Mall Customers", subtitle = "Using K-means Clustering")
屏幕截图:

输出:
码:
kCols=function(vec){cols=rainbow (length (unique (vec))) return (cols[as.numeric(as.factor(vec))])} digCluster<-k6$cluster; dignm<-as.character(digCluster); # K-means clusters plot(pcclust$x[,1:2], col =kCols(digCluster),pch =19,xlab ="K-means",ylab="classes") legend("bottomleft",unique(dignm),fill=unique(kCols(digCluster)))
屏幕截图:

输出:
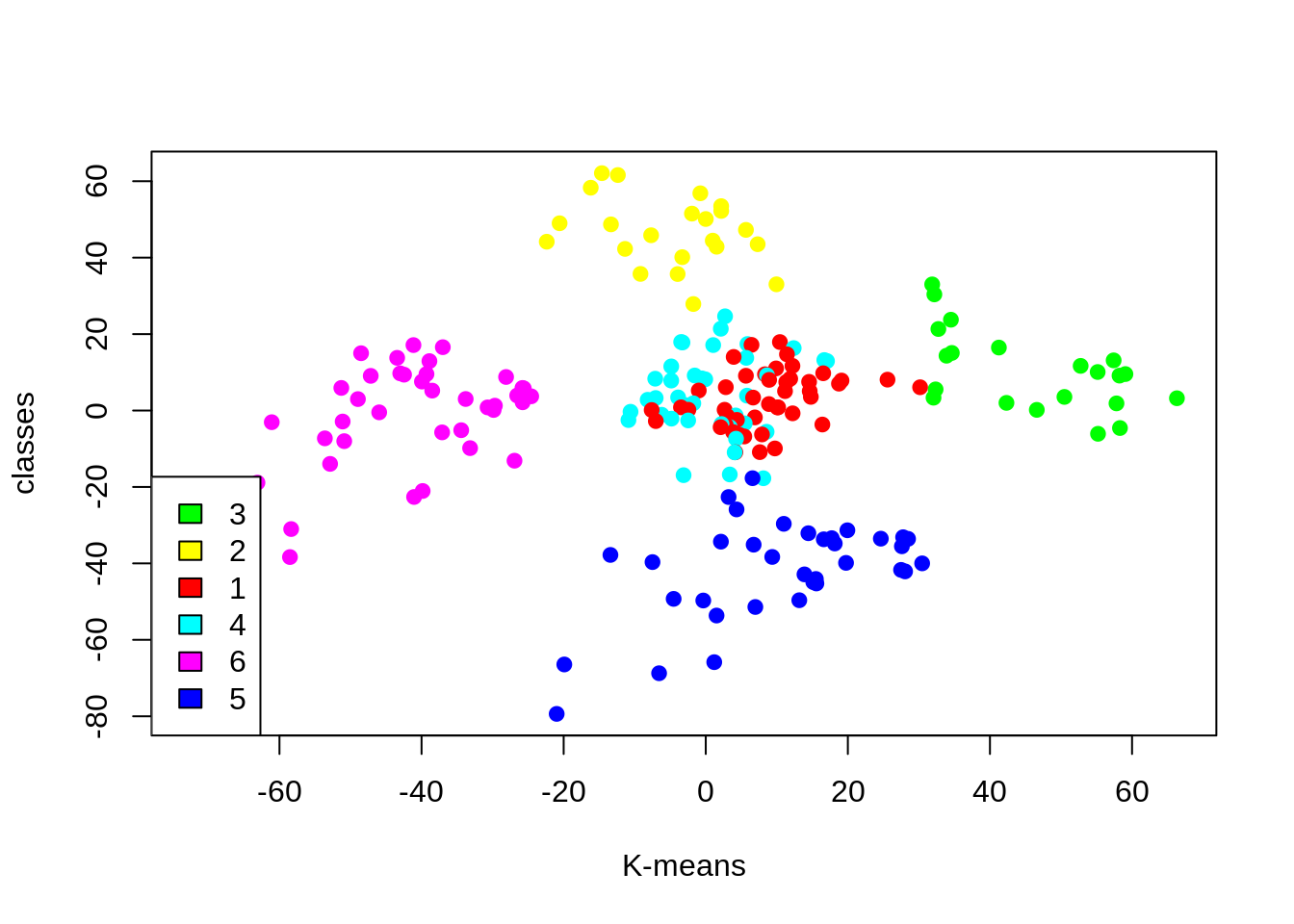
群集4和1 –这两个群集由具有中等PCA1和中等PCA2分数的客户组成。
群集6 –此群集代表具有较高PCA2和较低PCA1的客户。
群集5 –在此群集中,有些客户的PCA1中等而PCA2分数较低。
群集3 –此群集由PCA1收入高和PCA2高的客户组成。
群集2 –这包括PCA2高且年收入中等的客户。
随着集群的帮助下,我们可以了解变量要好得多,这促使我们采取慎重决策。通过识别客户,公司可以根据收入,年龄,支出模式等多个参数发布针对客户的产品和服务。此外,为了更好地进行细分,还考虑了更复杂的模式(例如产品评论)。
总结
在这个数据的科学项目,我们通过客户细分模型去了。我们开发了这个使用类机器学习作为一种非监督学习。具体来说,我们利用聚类算法称为K-means聚类。我们分析和可视化的数据,然后着手执行我们的算法。希望你喜欢使用R.机器学习的这个客户的细分项目
-
 支付宝扫一扫
支付宝扫一扫
-
 微信扫一扫
微信扫一扫