RNN本质上是在原有全连接神经网络的基础上,增加了一个时间轴的概念。所带来的影响是:同样的数据,不同的输入顺序,会得到不同的结果。这样的效果天生适合处理跟时间顺序(时序)有关的数据,比如语音、文本、翻译……,其实,随着RNN的发展,某些变种甚至还能巧妙地用在图像处理问题上,达到不输CNN的效果。
基于全连接神经网络发展而来的CNN和RNN,我们可以简单的把他俩的长处区分为:
CNN能「看懂」图形
RNN能「记住」顺序
RNN如此有效就在于它拥有记忆能力,尤其是LSTM(RNN的一个应用广泛的变种)更是在长期记忆方面有不俗的表现。
网上很多文章对于RNN的构成和运作原理已经介绍的很详细了。不过由于基础不同,笔者发现有些入门同学在阅读网上资料时对一些部分难以理解,这篇文章会侧重于用形象化讲给最基础的入门同学。有不准确的地方,还请指正!
先看一下之前学习的全连接神经网络
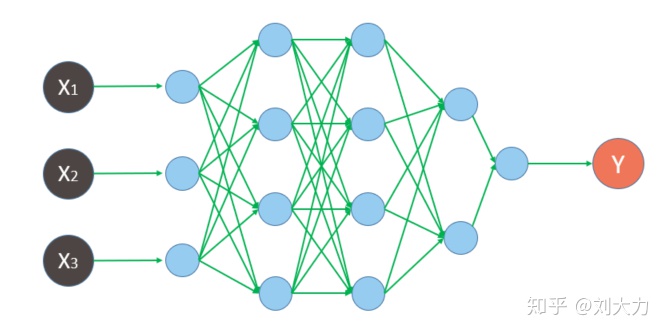
喂数据时的动态图

然后,为与网络上其他教程一致,先把整个网络旋转90度
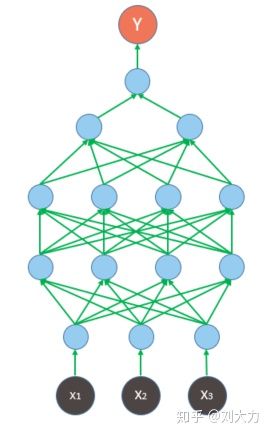
接着引入时间概念。

图上的t我们称为时间步(time_step),每个t称为1步,t1-t5为1个周期。
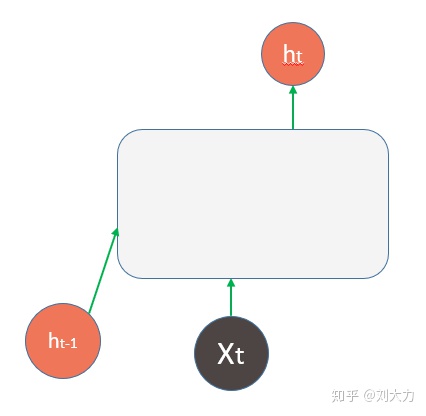
然后引入记忆概念。把上一个时间步产生的结果(  )同X一起输入进去
)同X一起输入进去

RNN之所以有记忆力,是因为在每个t完成后,其产生的结果会在下一个t开始时,与X一起输送给RNN运算,相当于输入中包含了之前所有t的「精华」
现在将RNN的运算部分包装起来,并把相应变量修改为惯例字母。其实普通RNN内部并非为多层网络,仅仅是一个tanh层。
这个图按时间轴展开,即为常见的RNN结构图
 图片来自《Understanding LSTM Networks》
图片来自《Understanding LSTM Networks》
很多初学者在接触time_step时,很容易与全神经网络下的batch混淆。下面我们区分一下。
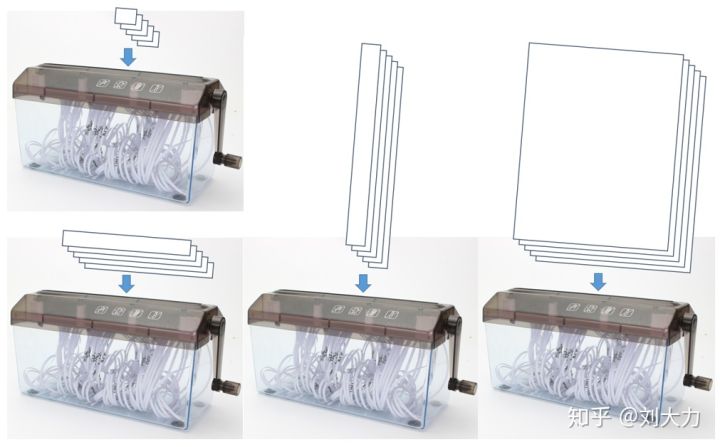
我们用碎纸做个比方。有一张A4纸,长宽分别为297*210 mm,现在要把纸塞进碎纸机里。
 图片来自淘宝
图片来自淘宝
在这个例子中,
A4纸就是数据,总数据量为297*210,
碎纸机是神经网络
输出的结果是粉碎的纸,这里我们先不管输出是什么样,只关注输入。
每次塞纸时,都要正拿A4纸,把210的一边冲着碎纸机的口塞入。
现在开始考虑各个参数的意义。
下图代表input_size=1,batch=1,喂给碎纸机的是一个1*1的小纸片,训练1000次代表喂1000次纸;

下图代表数据维度input_size=210,batch=1,也就说,数据本身发生了变化——增加维度了;

下图代表input_size=1,批次batch=297,数据本身没变,每次训练时进的数据量多了

相应的,下图就代表input_size=210,batch=297,一共只需要1次就能训练完所有数据。

以上是我们之前学习的全连接神经网络。
现在引入RNN。RNN保留了之前所有参数,并增加了参数time_step(时间步),对于这个例子,我们应该怎么理解这个新参数呢?
此刻你手中的纸突然有了厚度(10*297*210),碎纸机还是那台,纸变厚了,就必须切片才能塞进去,在这个例子中,纸被切成了10层。
RNN要求你,每次塞纸时,不管纸是什么形状(不管batch等于多少),都必须把10层纸依次、先后、全塞进去,才算一次完整的喂纸,中间不许停(time_step=10)
同时,每层纸在进纸时,还需要跟上层产生的碎纸片一起塞进去(
 )
)
至此,我们看到,batch依然保留,与time_step分别代表不同意义。
其实,从另一个角度也可以区分,time_step是神经网络的参数,网络建好了便不会改变;batch是训练参数,在训练时可根据效果随时调整。
-
 支付宝扫一扫
支付宝扫一扫
-
 微信扫一扫
微信扫一扫